

ほぼ素のRailsアプリだった「スピカとチロル」が本番環境で安定動作するまで
この記事は Akatsuki Advent Calendar 6日目の記事です。
前日は使用頻度の低いGCEインスタンスを組織一括で検知する方法でした。
ただ rails new しただけのアプリケーションであるスピカとチロルが、本番環境での安定動作が実現するまでにやったことをまとめました。
もくじ
前提
スケーラブルで堅牢なシステムを完成させたキラキラした話ではなく、小規模でサイズも大きくないサーバを無駄なく使えるようにするまでの話になります。 こんな方々におすすめです。
- ハッカソンや個人制作で動くWebアプリケーションを作ったことがあるものの、それを本番で動くシステムとして動作させた経験のない人
- スピカとチロルリリース初期に行っていたインフラ対応の裏側を知りたい人
- Mackerelのメトリクスの読み方に興味がある人(今回とても助けられました)
スピカとチロルの紹介
サーバ処理主体の半放置ゲームです。自動探索で拾ったアイテムを装備して、手動のRPG的なバトルでさらなる奥地をひたすら目指すタイプのゲームです。 考えると倒せるようになるボス戦、手をかけたらそれだけ探索効率の良さとしてフィードバックが返ってくる楽しさがウリです。
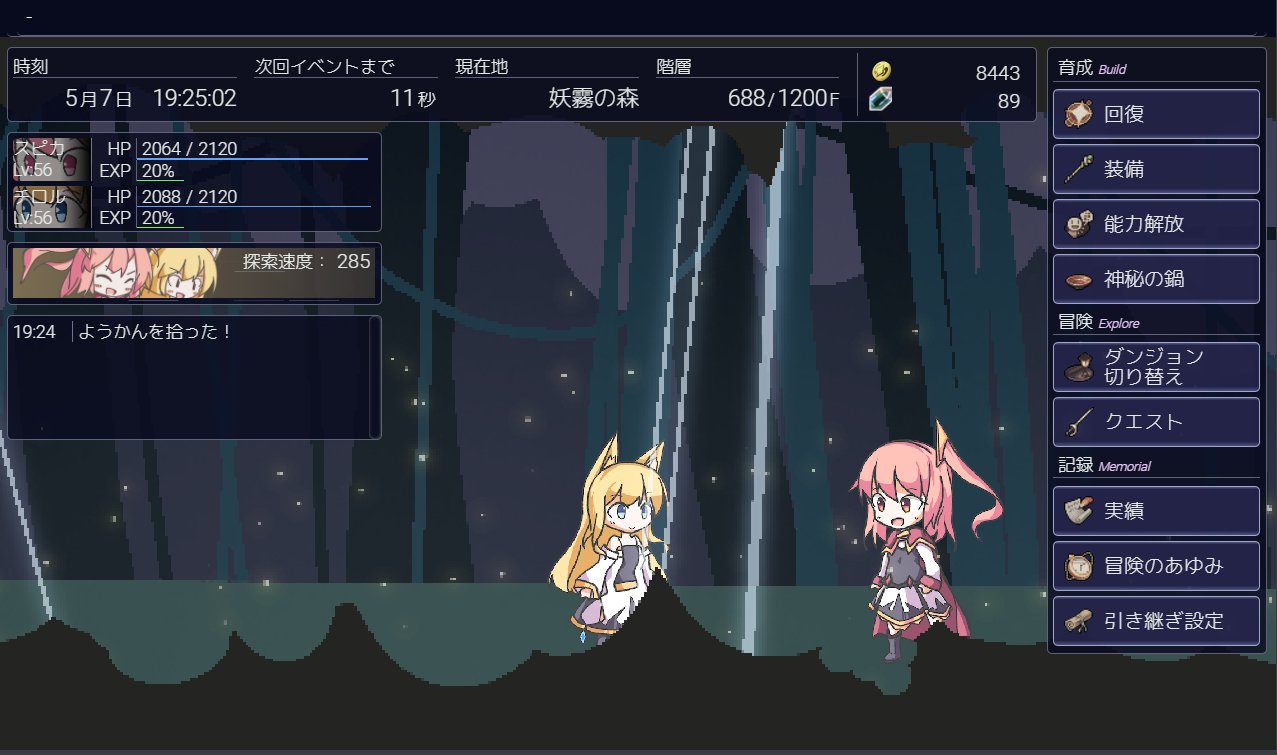

おおまかアーキテクチャ解説
シンプルに1台のEC2の中で全部受け切る前提にしておいて、受けきれなくなってから最悪スケールも可能アーキテクチャです。 ユーザの進捗データはキャッシュサーバ・DBのみに保存されているので、これらをインスタンス内から切り離して参照先を切り替えればアプリケーションサーバの数を増やせる作りです。 (結果的にそれが必要になる規模での大きな負荷は来ませんでしたが、予想外の大盛況に耐えられる構造というのは大いに開発の励みになりました)
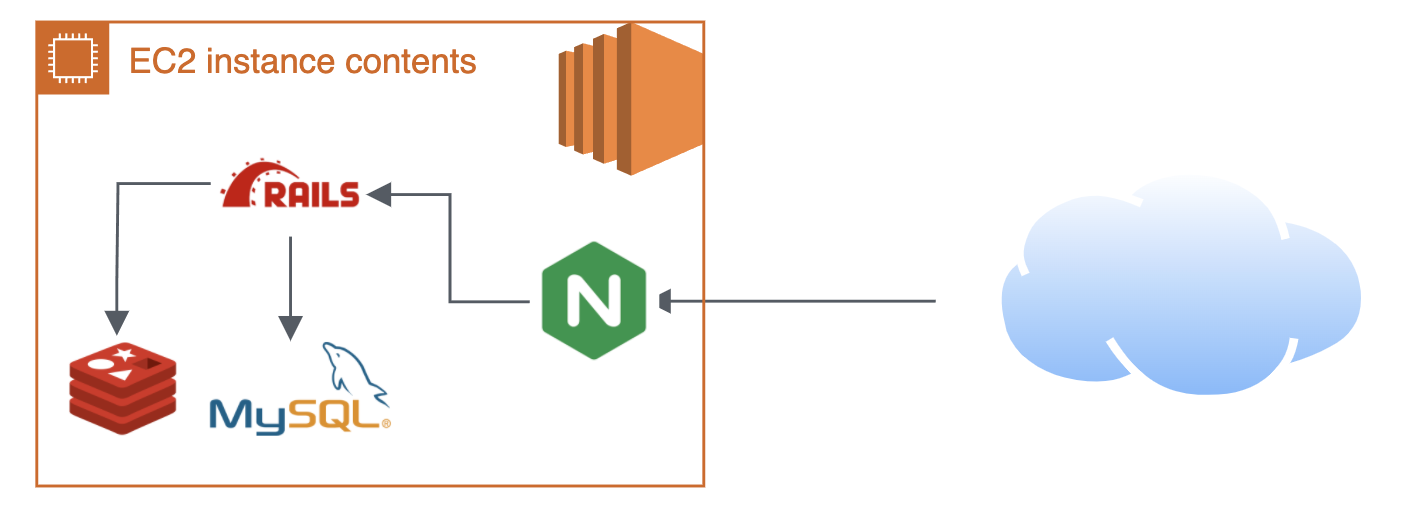
このゲームのインフラ的特徴
お金が絡まないので、必要なサービスレベルの水準は低い。
サーバが落ちたらゲームの評判が落ちて悔しいが、意地の領域。
個人の財布で活動しているので、サーバのリソースを可能な限り小さく保ちたい。
AWSのサービスを広範囲で使うほどに予算を食うので、1台のEC2サーバに押し込みたくなる。
半放置ゲームなのでつけっぱなしにするプレイスタイルが多い。
30秒に1回サーバに進捗を問い合わせており、通信の大部分はこれ。アクティブユーザの数に対してほぼ線形に負荷が上昇する。
ゲームロジック・APIレスポンスタイムには特段の問題がないことを検証済み。
身内向けのアルファ版を本番リリース3ヶ月前に本番とほぼ同様の構成で公開しており、その時はユーザ10人ほどを t3a.micro インスタンスで捌いた。
本番リリースからのタイムライン
いろいろな問題にぶつかりながら、なんとか本番のサーバが安定動作するまでの記録です。
2021/5/8 リリース
twitter でリリース告知を行いました。 静かなスタートを切ることができ、リツイート100件分からの流入で200人ほどが同時に遊ぶ状態になりましたが、特段の問題なく捌き切ることができました。 この時点ではプレイヤー数は累計で1000人程度です。
2021/6/26 13:17 ブログ経由での急な大量流入
リリース後しばらく落ち着いていましたが、Flashゲーを紹介する大手ブログで紹介されてアクセス急増。 Mackerelからの ロードアベレージ・CPU利用率のアラートで気づきました。 とりあえず本番環境に自分でもアクセスし、ゲームが動作していることを確認。
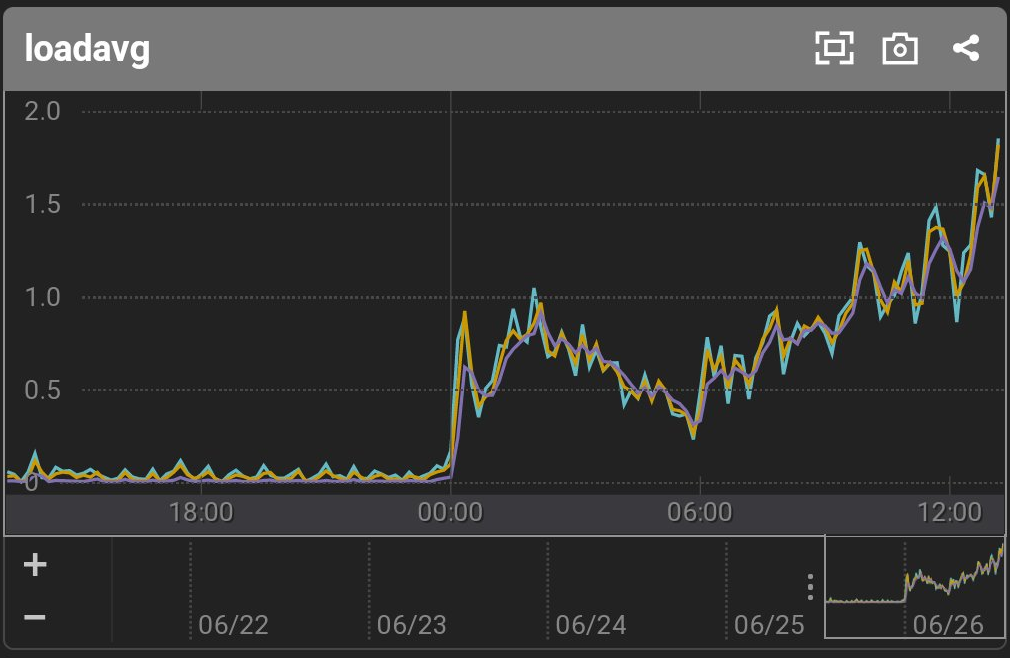
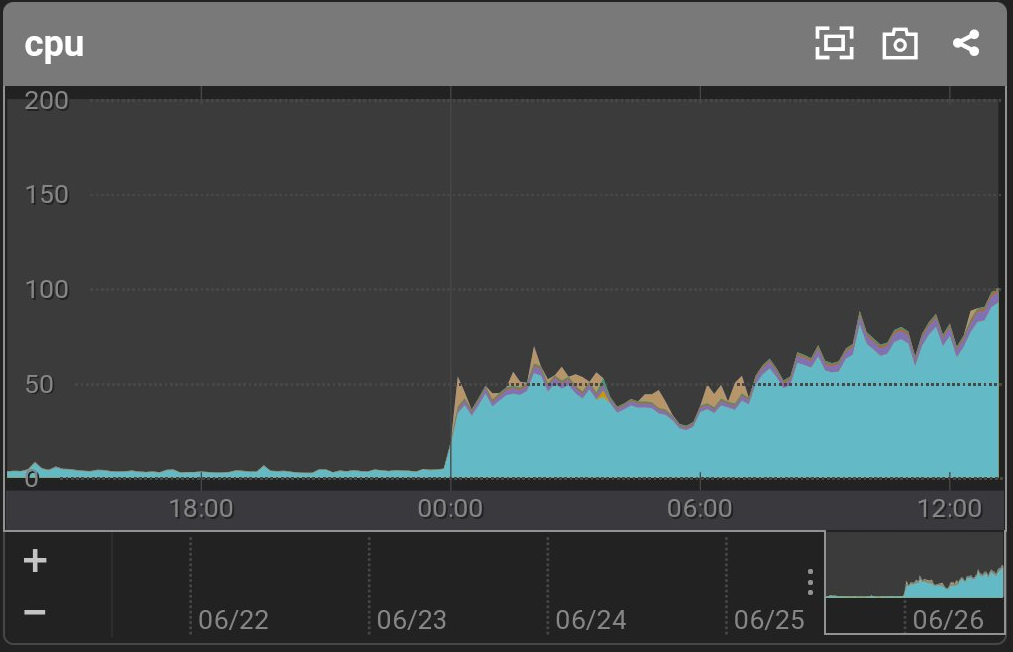
2021/6/26 22:40 ディスク使用率アラート
毎日行っているログローテーションによる圧縮が来る前にディスクが埋まりかけてアラートが発生しました。 そもそもディスク容量が16GBとかなり小さめだったので、EBSを無停止で拡張して対応。
サービスを停止せずにディスク容量を増やせるのはとてもありがたいですね。自宅サーバだとこうはいかないので、AWSの強みを活かせました。

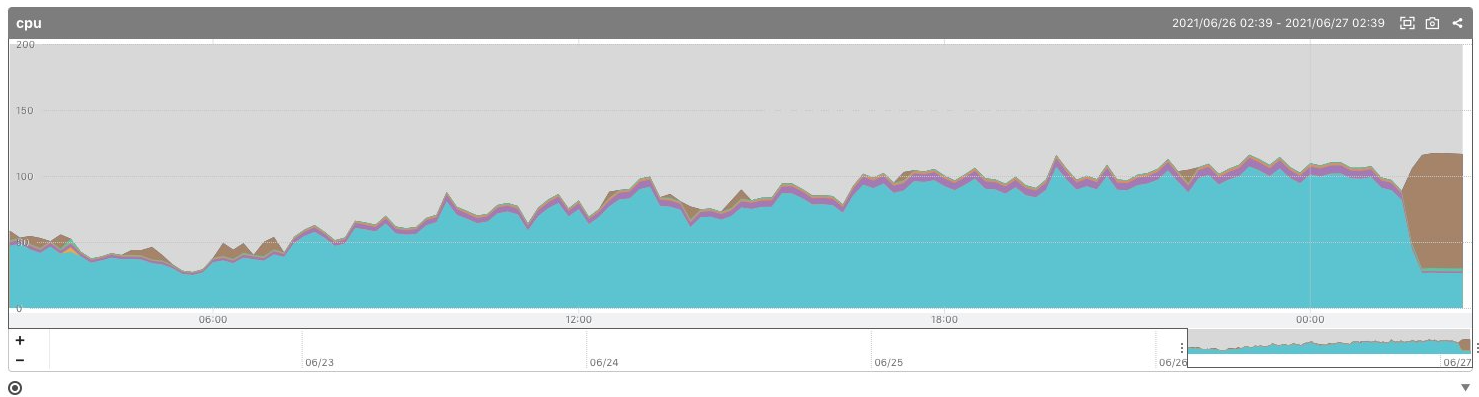
2021/6/27 02:46 CPUクレジット切れ
急にゲームが重くなったとの報告が入り、Mackerelを確認したところウェイトが増えていました。CPUクレジット切れですね。 t系インスタンスだったのであたり前で、事前にこういう事が起きるのは気付いていたことでしたが、EBSの方を対応してアラートが消えたので満足してしまっていました。本当にまずい障害を起こすときはこういう不注意がトリガーになりますね...
今後のアクセスの傾向が読めないこともあり、安全をとって c5.large インスタンスに変更しました。 このタイミングで、累計プレイヤー数が2000人を突破しています。半日で累計プレイヤー数が倍になりました。
2021/6/27 10:00 レイテンシー悪化 / マルチプロセスに変更
昨晩インスタンスのスケールアップをしたにもかかわらず、ロードアベレージは数時間で同水準まで上昇してしまいました。 ブログやtwitterでもまた重くなったとの報告が上がり始めます。 Mackerelの指標を見る限りCPU利用率100% ( 2コアなので 200%が最大 ) 付近で上限に達しており、インスタンスの性能を使いきれていないように見えます。 インスタンスにSSHで入り、top を確認するとCPU利用率100%でひとりで頑張っているrubyのプロセスを発見しました。1プロセスで捌き切れる限度まで達していたようです。 調べてみたところ、Rails標準の Puma の設定では、1プロセスで動作するようになっていました。puma のデプロイに関する資料を参考にしつつ、pumaも2プロセスで動作させるようにしたところ、体感の遊び心地は大幅に改善して意図通りのゲーム体験が戻ってきました。
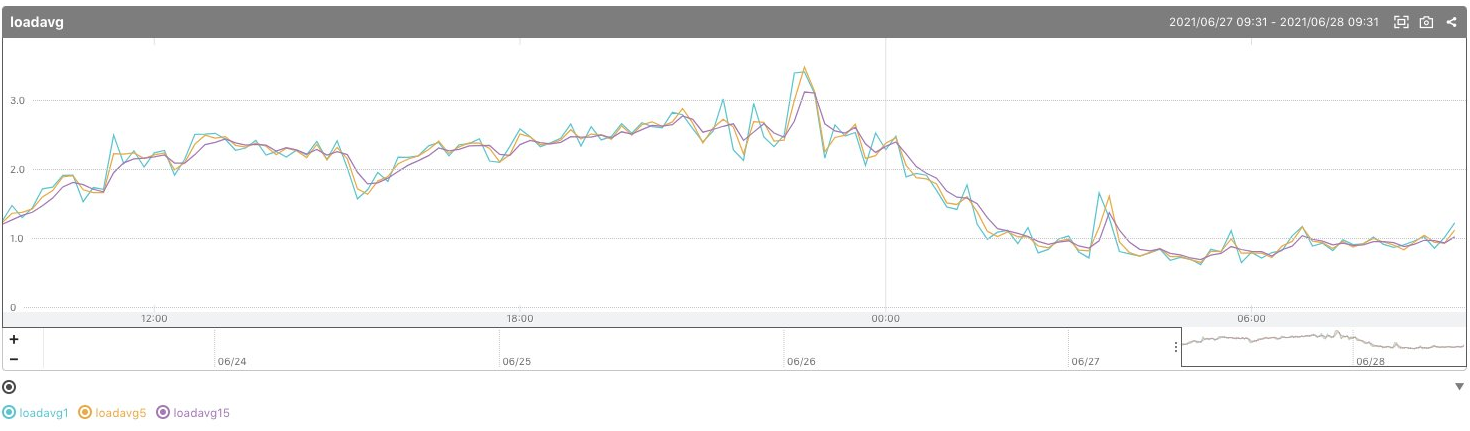
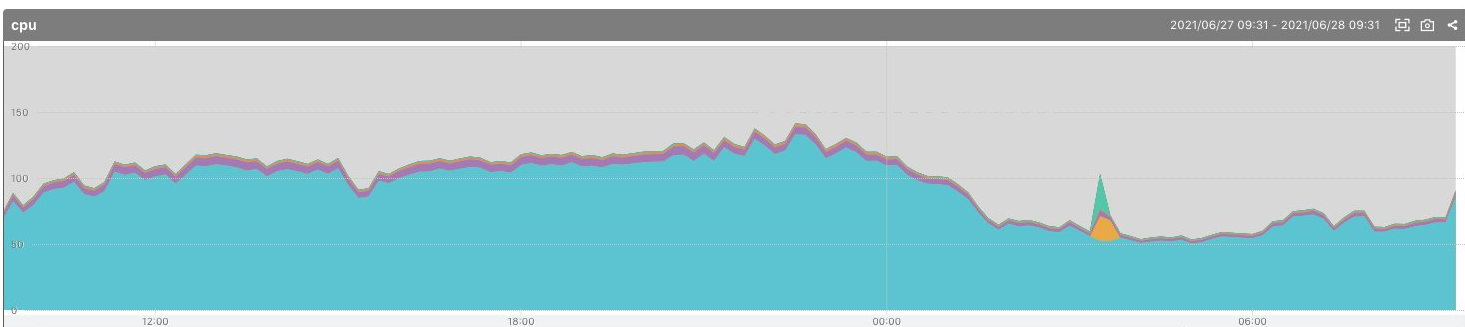
2021/6/28 10:00 夜を乗り切った
ゲームの遊び心地が改善した状態で一晩の山を耐え切り、無事安定動作させることができました。 その後数日すこしずつ負荷が伸び、最大CPU利用率140%程度まで逼迫しましたがこの構成で耐えきることができました。 無事ブログ経由の流入層みんなにゲームを遊んでもらうことに成功しました。
いま
8000人ほどのアカウントがあり、1500人にラスボスを倒してもらえました。予想以上の大繁盛です。作った甲斐がありました。
ふりかえり
アクセス急増に際して発生した3つの障害対応のふりかえりです。
よかったこと
事前に監視体制は敷けていた
Mackerel の標準メトリクスだけとはいえ、メトリクス取得・監視体制ができていたので迅速な対応ができました。 サーバの体感が重かったのは累計3時間程度、サーバ停止も累計15分程度に抑えられ、ゲーム体験を提供するという観点ではほぼ成功といえる結果になりました。
大量流入前にゲームロジックの方の検証ができていた
身内でのアルファ版公開と本公開後の1ヶ月半のゆるいアクセス時期にゲームロジック側の検証が丁寧にできており、本流入がやってきたタイミングではインフラの拡張の方に専念することができました。 今回の対応は「計算資源を使い切る」ことだけにフォーカスできていましたが、この対応をしつつバグ修正やバランス調整、APIのレスポンス速度改善に気を回すことになっていたら大変でした。
よりよくできたこと
t系インスタンスを本番で使うのをやめよう
そもそもAWSは、t系インスタンスを本番稼働させるのを推奨していません。
ほんの少し割安なのと、いつも使っているからという理由で本番でもt系インスタンスを利用していました。 CPUクレジットの上限的に、いざアクセスがやってきて8~12時間程度がタイムリミットになる爆弾を抱えることになります。
可能であればやっぱり負荷試験をしよう
今回起きた3つの障害であるディスクアラート、t系インスタンスのCPUクレジット制限、CPU1コア以上使えない状態はすべて事前に負荷試験をしておけば発見できるものでした。
Locustなどコード管理できる便利な負荷試験のための道具は揃っているので、主要なAPIを一通り叩くシナリオを作成して本番環境がどの程度までアクセスをさばくことができるのか把握できていると良かったですね。 今回はゲームが完成した瞬間にさっそく世に出してしまいました。
おわりに
作っていた時の想定の数倍のアクセスがやってきて、ゲーム開発者としてとても嬉しい体験ができました。 自分の作ったゲームにまさか300件近いコメントを貰って、攻略wikiが作られるなんて思っていませんでした。遊んでいただきまして感謝です。